Identify failed rows in an Expectation
Quickly identifying problematic rows can reduce troubleshooting effort when an Expectation fails. After identifying the failed row, you can modify or remove the value in the table and run the Expectation again.
The following table shows the sample data that is used to demonstrate failed row identification. The sample data is webpage visitor events.
| event_id | visit_id | date | event_type |
|---|---|---|---|
| 0 | 1470408760 | 20220104 | page_load |
| 1 | 1470429409 | 20220104 | page_load |
| 2 | 1470441005 | 20220104 | page_view |
| 3 | 1470387700 | 20220104 | user_signup |
| 4 | 1470438716 | 20220104 | purchase |
| 5 | 1470420524 | 20220104 | download |
In the example code you'll run, you'll use a preconfigured Checkpoint named my_checkpoint that runs an Expectation Suite named visitors_exp that contains the Expectation type ExpectColumnValuesToBeInSet on the event_type column. To demonstrate an Expectation failure, you'll set the set parameter to ["page_load", "page_view]so the rows with user_signup, purchase, and download fail.
The example code is located in the primary_keys_in_validation_results GitHub repository.
Prerequisites
- pandas
- Spark
- SQLAlchemy
pandas
Identify failed rows using pandas.
Import the Great Expectations module and instantiate a Data Context
Use the get_context() method to create a new Data Context:
import great_expectations as gx
context = gx.get_context(project_root_dir=".")
Import the Checkpoint
Run the following code to import the example Checkpoint:
my_checkpoint = context.get_checkpoint("my_checkpoint")
Set the unexpected_index_column_names parameter
The failed rows are defined as values in the unexpected_index_column_names parameter. In the following example, you are setting the parameter to event_id to return the event_ids of the rows that fail the Expectation. However, unexpected_index_column_names can also return a list of columns that are representative of the failed rows. The Checkpoint also returns the unexpected_index_query, which you can use to retrieve the full set of failed results.
In the following example, you're setting the result_format to COMPLETE to return the full set of results. For more information about result_format, see Result format.
result_format: dict = {
"result_format": "COMPLETE",
"unexpected_index_column_names": ["event_id"],
}
Run Checkpoint using result_format
Run the following code to apply the updated result_format to every Expectation in your Suite and pass it directly to the run() method:
results = my_checkpoint.run(result_format=result_format)
Review Validation Results
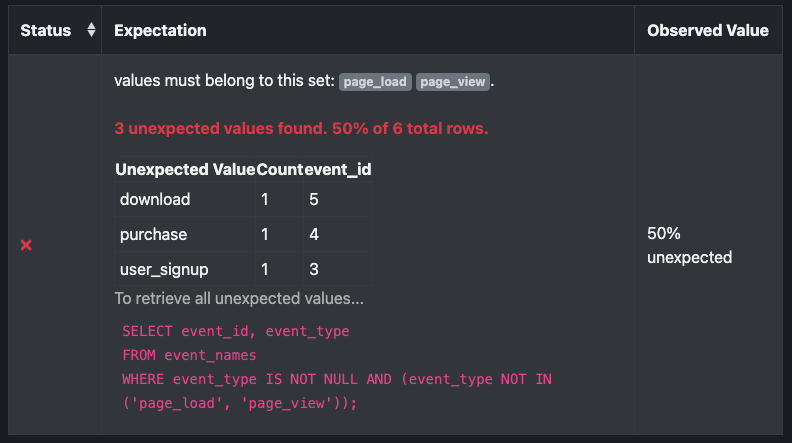
After you run the Checkpoint, a dictionary for each failed row is returned. Each dictionary contains the row’s identifier and the failed value.
The following is an example of the information returned after running the Checkpoint. For pandas, a filter condition on the DataFrame is included.
{
"element_count": 6,
"unexpected_count": 3,
"unexpected_percent": 50.0,
"partial_unexpected_list": ["user_signup", "purchase", "download"],
"unexpected_index_column_names": ["event_id"],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 50.0,
"unexpected_percent_nonmissing": 50.0,
"partial_unexpected_index_list": [
{"event_type": "user_signup", "event_id": 3},
{"event_type": "purchase", "event_id": 4},
{"event_type": "download", "event_id": 5},
],
"partial_unexpected_counts": [
{"value": "download", "count": 1},
{"value": "purchase", "count": 1},
{"value": "user_signup", "count": 1},
],
"unexpected_list": ["user_signup", "purchase", "download"],
"unexpected_index_list": [
{"event_type": "user_signup", "event_id": 3},
{"event_type": "purchase", "event_id": 4},
{"event_type": "download", "event_id": 5},
],
"unexpected_index_query": "df.filter(items=[3, 4, 5], axis=0)",
}
Open the Data Docs
Run the following code to open the Data Docs:
context.open_data_docs()
The following image shows the unexpected_index_list values are displayed as part of the validation output. Click To retrieve all unexpected values to open the filter condition to retrieve all unexpected values.
Spark
Identify failed rows using Spark.
Import the Great Expectations module and instantiate a Data Context
Use the get_context() method to create a new Data Context:
import great_expectations as gx
context = gx.get_context(project_root_dir=".")
Import the Checkpoint
Run the following code to import the example Checkpoint:
my_checkpoint = context.get_checkpoint("my_checkpoint")
Set the unexpected_index_column_names parameter
The failed rows are defined as values in the unexpected_index_column_names parameter. In the following example, you are setting the parameter to event_id to return the event_ids of the rows that fail the Expectation. However, unexpected_index_column_names can also return a list of columns that are representative of the failed rows. The Checkpoint also returns the unexpected_index_query, which you can use to retrieve the full set of failed results.
In the following example, you're setting the result_format to COMPLETE to return the full set of results. For more information about result_format, see Result format.
result_format: dict = {
"result_format": "COMPLETE",
"unexpected_index_column_names": ["event_id"],
}
Run Checkpoint using result_format
Run the following code to apply the updated result_format to every Expectation in your Suite and pass it directly to the run() method:
results = my_checkpoint.run(result_format=result_format)
Review Validation Results
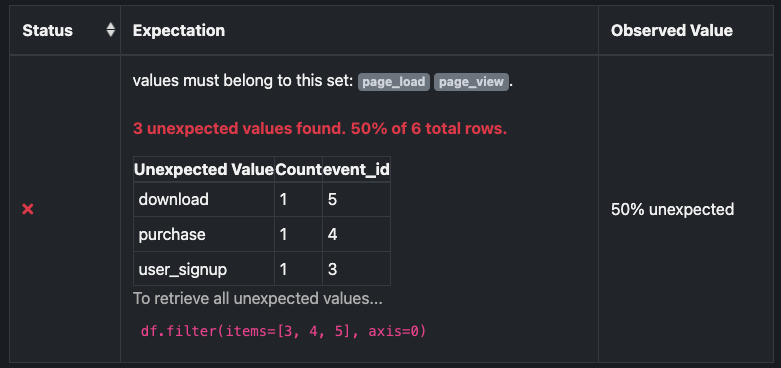
After you run the Checkpoint, a dictionary for each failed row is returned. Each dictionary contains the row’s identifier and the failed value.
The following is an example of the information returned after running the Checkpoint. For Spark, a filter condition on the DataFrame is included.
{
"element_count": 6,
"unexpected_count": 3,
"unexpected_percent": 50.0,
"partial_unexpected_list": ["user_signup", "purchase", "download"],
"unexpected_index_column_names": ["event_id"],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 50.0,
"unexpected_percent_nonmissing": 50.0,
"partial_unexpected_index_list": [
{"event_id": 3, "event_type": "user_signup"},
{"event_id": 4, "event_type": "purchase"},
{"event_id": 5, "event_type": "download"},
],
"partial_unexpected_counts": [
{"value": "download", "count": 1},
{"value": "purchase", "count": 1},
{"value": "user_signup", "count": 1},
],
"unexpected_list": ["user_signup", "purchase", "download"],
"unexpected_index_list": [
{"event_id": 3, "event_type": "user_signup"},
{"event_id": 4, "event_type": "purchase"},
{"event_id": 5, "event_type": "download"},
],
"unexpected_index_query": "df.filter(F.expr((event_type IS NOT NULL) AND (NOT (event_type IN (page_load, page_view)))))",
}
Open the Data Docs
Run the following code to open the Data Docs:
context.open_data_docs()
The following image shows the unexpected_index_list values are displayed as part of the validation output. Click To retrieve all unexpected values to open the filter condition to retrieve all unexpected values.
SQLAlchemy
Identify failed rows using SQLAlchemy.
Import the Great Expectations module and instantiate a Data Context
Use the get_context() method to create a new Data Context:
import great_expectations as gx
context = gx.get_context(project_root_dir=".")
Import the Checkpoint
Run the following code to import the example Checkpoint:
my_checkpoint = context.get_checkpoint("my_checkpoint")
Set the unexpected_index_column_names parameter
The failed rows are defined as values in the unexpected_index_column_names parameter. In the following example, you are setting the parameter to event_id to return the event_ids of the rows that fail the Expectation. However, unexpected_index_column_names can also return a list of columns that are representative of the failed rows. The Checkpoint also returns the unexpected_index_query, which you can use to retrieve the full set of failed results.
In the following example, you're setting the result_format to COMPLETE to return the full set of results. For more information about result_format, see Result format.
result_format: dict = {
"result_format": "COMPLETE",
"unexpected_index_column_names": ["event_id"],
}
Run Checkpoint using result_format
Run the following code to apply the updated result_format to every Expectation in your Suite and pass it directly to the run() method:
results = my_checkpoint.run(result_format=result_format)
Review Validation Results
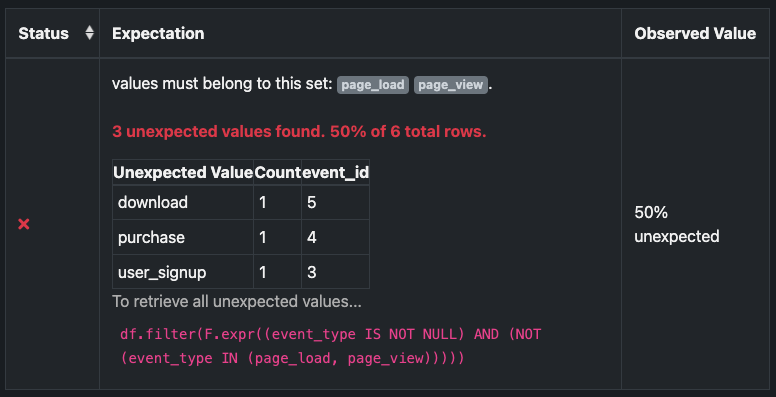
After you run the Checkpoint, a dictionary for each failed row is returned. Each dictionary contains the row’s identifier and the failed value.
The following is an example of the information returned after running the Checkpoint. For SQLAlchemy, the output includes a query that can be used directly against the database backend.
{
"element_count": 6,
"unexpected_count": 3,
"unexpected_percent": 50.0,
"partial_unexpected_list": ["user_signup", "purchase", "download"],
"unexpected_index_column_names": ["event_id"],
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_percent_total": 50.0,
"unexpected_percent_nonmissing": 50.0,
"partial_unexpected_index_list": [
{"event_id": 3, "event_type": "user_signup"},
{"event_id": 4, "event_type": "purchase"},
{"event_id": 5, "event_type": "download"},
],
"partial_unexpected_counts": [
{"value": "download", "count": 1},
{"value": "purchase", "count": 1},
{"value": "user_signup", "count": 1},
],
"unexpected_list": ["user_signup", "purchase", "download"],
"unexpected_index_list": [
{"event_id": 3, "event_type": "user_signup"},
{"event_id": 4, "event_type": "purchase"},
{"event_id": 5, "event_type": "download"},
],
"unexpected_index_query": "SELECT event_id, event_type \nFROM event_names \nWHERE event_type IS NOT NULL AND (event_type NOT IN ('page_load', 'page_view'));",
}
Open the Data Docs
Run the following code to open the Data Docs:
context.open_data_docs()
The following image shows the unexpected_index_list values are displayed as part of the validation output. Click To retrieve all unexpected values to view the SQL query that you can use to retrieve all unexpected values.