Conditional Expectations
Sometimes one may hold an Expectation not for a dataset in its entirety but only for a particular subset. Alternatively, what one expects of some variable may depend on the value of another. One may, for example, expect a column that holds the country of origin to not be null only for people of foreign descent.
Great Expectations allows you to express such Conditional Expectations via a row_condition argument that can be passed
to all Dataset Expectations.
Today, conditional Expectations are available only for the Pandas but not for the Spark and SQLAlchemy backends. The feature is experimental. Please expect changes to API as additional backends are supported.
For Pandas, the row_condition argument should be a boolean expression string, which can be passed
to pandas.DataFrame.query() before Expectation Validation (see
the Pandas docs.
Additionally, the condition_parser argument must be provided, which defines the syntax of conditions. Since the
feature is experimental and only available for Pandas this argument must be set to "pandas" by default, thus,
demanding the appropriate syntax. Other engines might be implemented in the future.
The feature can be used, e.g., to test if different encodings of identical pieces of information are consistent with each other. See the following example setup:
import great_expectations as ge
my_df = ge.read_csv("./tests/test_sets/Titanic.csv")
my_df.expect_column_values_to_be_in_set(
column='Sex',
value_set=['male'],
row_condition='SexCode==0'
)
This will return:
{
"success": true,
"result": {
"element_count": 851,
"missing_count": 0,
"missing_percent": 0.0,
"unexpected_count": 0,
"unexpected_percent": 0.0,
"unexpected_percent_nonmissing": 0.0,
"partial_unexpected_list": []
}
}
It is also possible to add multiple Expectations of the same type to the Expectation Suite for a single column. At most one Expectation can be unconditional while an arbitrary number of Expectations -- each with a different condition -- can be conditional.
my_df.expect_column_values_to_be_in_set(
column='Survived',
value_set=[0, 1]
)
my_df.expect_column_values_to_be_in_set(
column='Survived',
value_set=[1],
row_condition='PClass=="1st"'
)
# The second Expectation fails, but we want to include it in the output:
my_df.get_expectation_suite(
discard_failed_expectations=False
)
This results in the following Expectation Suite:
{
"expectation_suite_name": "default",
"expectations": [
{
"meta": {},
"kwargs": {
"column": "Survived",
"value_set": [0, 1]
},
"expectation_type": "expect_column_values_to_be_in_set"
},
{
"meta": {},
"kwargs": {
"column": "Survived",
"value_set": [1],
"row_condition": "PClass==\"1st\"",
"condition_parser": "pandas"
},
"expectation_type": "expect_column_values_to_be_in_set"
}
],
"data_asset_type": "Dataset"
}
You should not use single quotes nor \n inside the specified row_condition (see examples below). Otherwise a bug may be introduced when running great_expectations suite edit from the CLI.
row_condition="PClass=='1st'" # never use simple quotes inside !!!
row_condition="""
PClass=="1st"
""" # never use \\n inside !!!
Data Docs and Conditional Expectations
Conditional Expectations are displayed differently from standard Expectations in the Data Docs. Each Conditional Expectation is qualified with if 'row_condition_string', then values must be...
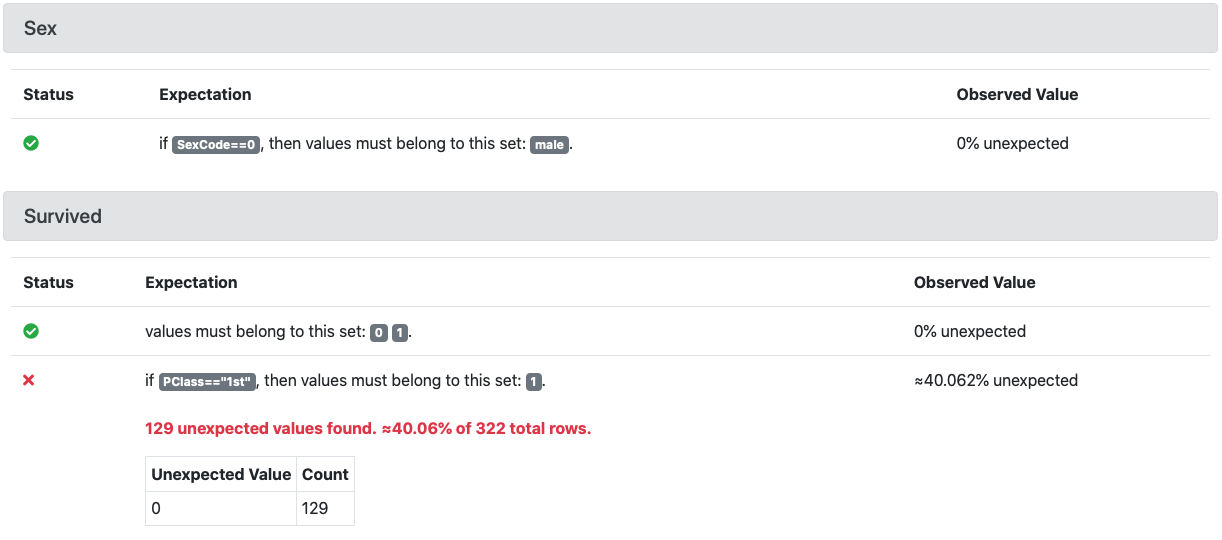
If 'row_condition_string' is a complex expression, it will be split into several components for better readability.
Scope and limitations
While conditions can be attached to most Expectations, the following Expectations cannot be conditioned by their very
nature and therefore do not take the row_condition argument:
expect_column_to_existexpect_table_columns_to_match_ordered_listexpect_table_column_count_to_be_betweenexpect_table_column_count_to_equal
For more information, see the Data Docs feature guide.